How to set up automatic SQL dumps from an EC2 hosted DB to S3 bucket

I am a dedicated double certified AWS Engineer with 10 years of experience, deeply immersed in cloud technologies. My expertise lies in a broad array of AWS services, including EC2, ECS, RDS, and CloudFormation. I am adept at safeguarding cloud environments, facilitating migrations to Docker and ECS, and improving CI/CD workflows with Git and Bitbucket.
While my primary focus is on AWS and cloud system administration, I also have a history in software engineering, particularly in Javascript-based (Node.js, React) and SQL.
In my free time I like to employ no-code/low code tools to create AI driven automations on my self hosted home lab.
This guide
This guide covers automated, regular SQL dumps to S3.
The AWS services to use for this are:
Systems manager “runcommand” feature to start the backup
S3 to have the backup stored
A Lambda function that does the runcommand operation
Eventbridge to schedule the lambda execution
Prerequisites:
- AWS Session manager (within Systems manager)
Advantages
You're not required to have a separate machine doing backups or use the DB host EC2 for this purpose.
No need to open any inbound ports (beyond outbound port 443 to systems manager client EP)
You can add logging and alerts to Cloudwatch to complement your existing logging
All backup would still be at a central place within Lambda and Eventbridge
Data traffic goes straight to database to S3 (no intermediary)
Disadvantages
A little long to set this up
Costs a tiny bit of money
No charge for => RunCommand, Session manager, EventBridge(free tier), Lambda (free tier),
Small charge for => S3, depending on DB size
Set up
Session manager
Make sure you have Session manager enabled and working with the EC2 that hosts the database
Lambda setup
Create a lambda with the following code:
import boto3
from botocore.exceptions import ClientError
def lambda_handler(event, context):
ssm = boto3.client('ssm')
instance_id = 'i-123456789'
database_user = 'db_user'
database_password = 'db_password'
database_name = 'db_name'
bucket_name = 'db-backups-bucket'
backup_file = 'backup_filename'
# The command to backup the database and upload to S3
backup_command = f"mysqldump -h 127.0.0.1 -u {database_user} -p{database_password} {database_name} | aws s3 cp - s3://{bucket_name}/{backup_file}_$(date +%Y%m%d).sql"
response = ''
try:
response = ssm.send_command(
InstanceIds=[
instance_id,
],
DocumentName='AWS-RunShellScript', # runs commands in the EC2 instance
Parameters={
'commands': [backup_command]
},
)
print(f"Command sent to instance {instance_id}. Response: {response}")
except ClientError as e:
print(f"Unexpected error when sending command to EC2 instance: {e}")
return {
'statusCode': 200,
'body': f"Command sent to instance {instance_id}. Command ID: {response['Command']['CommandId']}"
}
This will create an IAM ROLE for this Lambda function. Add this extra permission to the role (beyond the Log creation one that was added automatically on creation)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "ssm:SendCommand",
"Resource": [
"arn:aws:ec2:region:account:instance/i-123456789",
"arn:aws:ssm:region::document/AWS-RunShellScript"
]
}
]
}
This will give permission to your lambda function to run a shell script on a particular EC2 machine.
You can test this code by clicking "Test" and run it with no test input.
You'll either see an error => in this case it's probably a permission issue
You see no error => your shell script run, however it may have failed.
You can look at the execution logs in Run Command within Systems Manager and see something like this:

Clicking on the Failed item, you can see some details about the error:
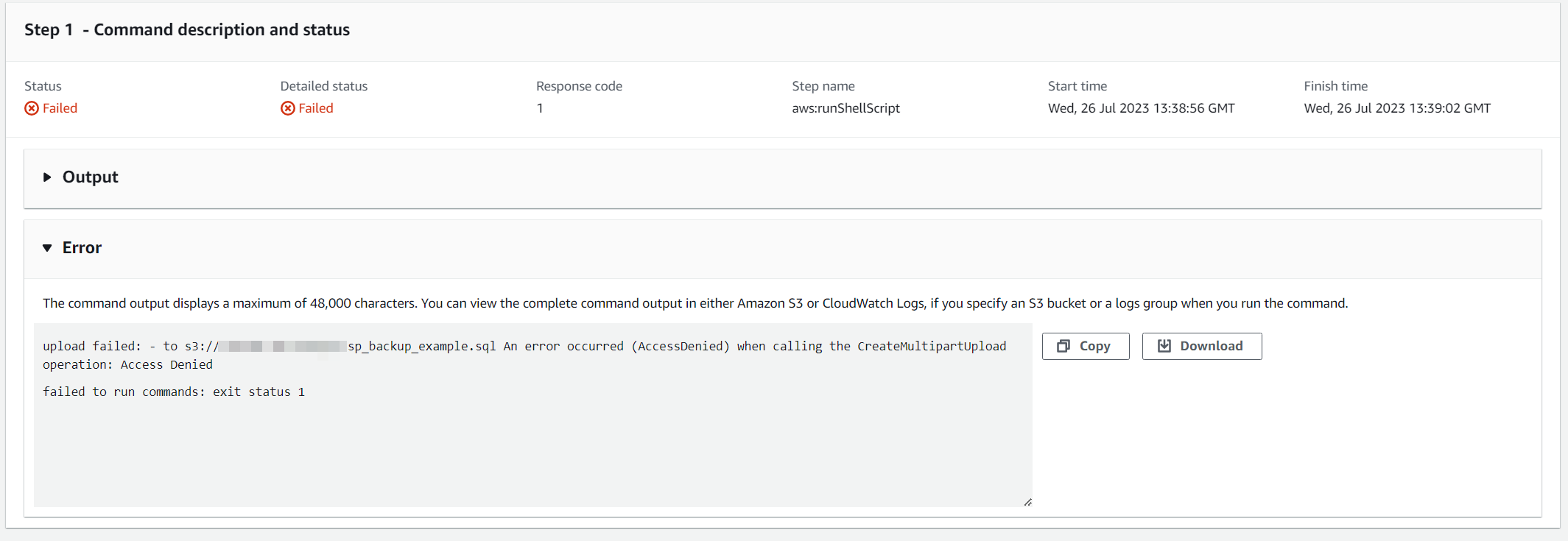
As at this point this isn't set up fully, you'll probably see an error corresponding to not having access to S3. Let's do that next!
S3 setup
Make sure you have a bucket you want to place the backups in. Please don't have this bucket public 🙂
Add an IAM role to the EC2 machine to allow upload to S3 (this way Lambda isn't required to handle large amounts of data or wait until execution finishes)
This policy worked for me to access the bucket. It omits delete permission for safety.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "arn:aws:s3:::*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::db-backups-bucket"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:GetObjectAcl",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
"s3:ListBucketMultipartUploads"
],
"Resource": [
"arn:aws:s3:::db-backups-bucket",
"arn:aws:s3:::db-backups-bucket/*"
]
}
]
}
Once this is done, re-test your lambda and it should work.
You can verify that the SQL backup file is in S3
Eventbridge
Go to Eventbridge Scheduler (it's a new feature).
Create a daily schedule to run a Lambda function:
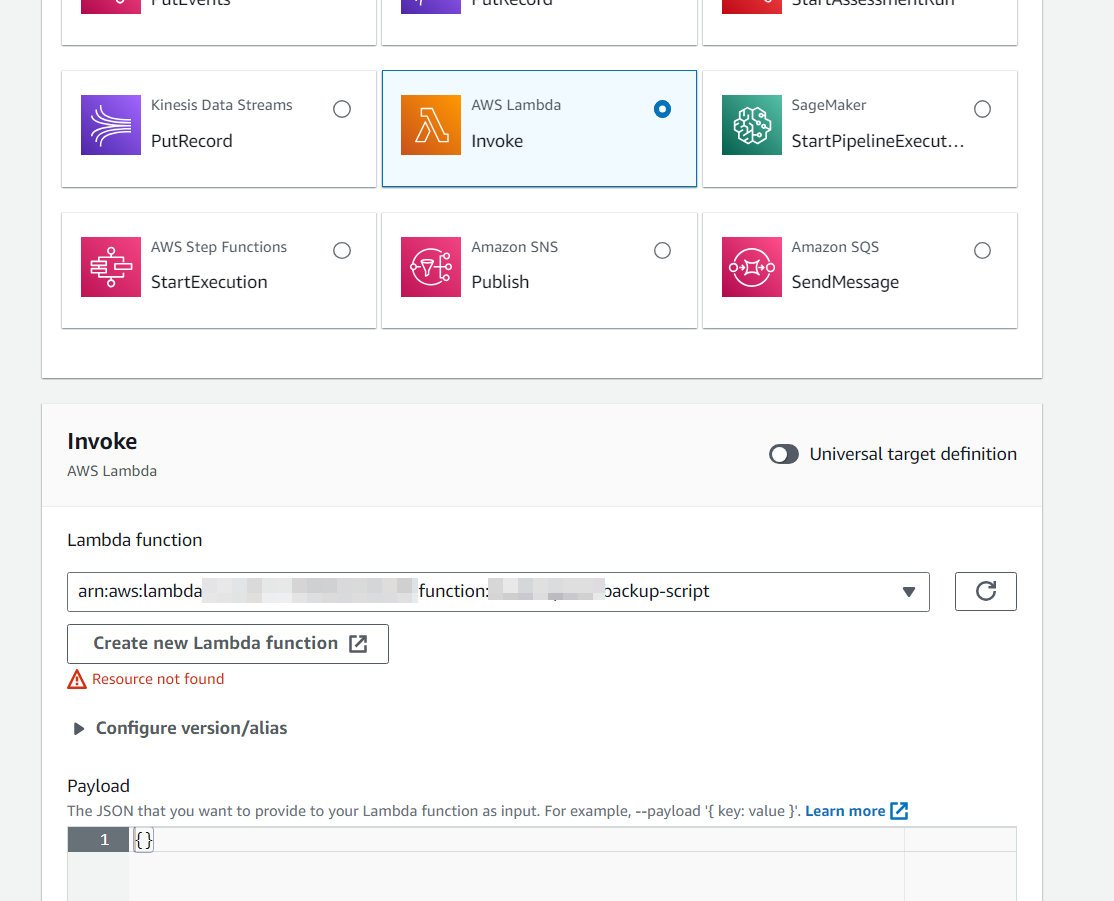
Eventbridge then will create an IAM role for itself to give itself permissions to execute the Lambda function (or you can use your own)
Once this is done, you have a functioning daily backup.
Some things to improve
As currently S3 will keep the backup forever, there's an option here to delete the latest one regularly within S3 lifecycle roles.
Create an alarm via cloudwatch to notify of any issues with the backup
Regularly check the integrity of the backups




